









.svg)






This is the second part in a StackStorm tutorial series:
- Part 1: DevOps Automation using StackStorm - Getting Started
- Part 2: DevOps Automation using StackStorm- Deploying with Ansible
- Part 3: DevOps Automation using StackStorm - Cloud Deployment via BitOps
- Part 4: DevOps Automation using StackStorm - BitOps Secrets Management
To complete this tutorial you will need:
- ansible
- A Linux server with basic internet connectivity
If you prefer skipping ahead to the final solution, the code created in this tutorial is on Github.
In the last article, we: deployed a StackStorm (ST2) instance, created our first pack, integrated it with an available community pack, and used them to demonstrate several basic concepts achieving basic Continuous Integration (CI) for our custom pack in the process.
I hope that article proved to pique your interest, and have been able take that information to spin up some custom actions of your own alongside exploring some of the features StackStorm has on offer.
However, as we look ahead and our deployment grows in our environment, becoming more integral to day to day operations, we look at being able to replicate it. Either to meet expanding resource growth needs, advanced development workflows, or for resiliency and disaster recovery.
Individually managing the installs using the one-line method or other manual installs is not sustainable for long periods of time so we need some other way of deploying what we have created so far.
Ansible is a perfect tool for taking what we have already in our pack, config file, and setup tasks and abstracting that into creating a repeatable playbook. It just so happens StackStorm has playbooks available that are easily modified to suit our needs.
The Plan
The available StackStorm Ansible playbooks are modular which makes it easy for us to incorporate our own changes without modifying the code-base at large. In this section we'll simply create our own Ansible role to handle the few configuration steps that we previously had to manually perform.
Once we have our new Ansible role, instead of using the one-line install, we'll simply run our modified Ansible playbook file and include our role with it. Like magic our instance will be deployed with our pack, the git pack dependency, our github_token in the encrypted data store, and our sensors monitoring for pack changes.
We'll start by simply cloning the ansible-st2 GitHub repo which contains the playbooks and roles we will be using as our basis, after which we will drop in our hand-crafted role.
git clone https://github.com/StackStorm/ansible-st2
Now let's get to it!
Role Reversal
Our Ansible Role will be quite simple, as we only need to complete a couple actions to configure the git pack. The ansible-st2 playbooks have functionalities that allow us to specify packs to install when we run the playbook which gets us part way there, however we still need to create a Role to complete the git pack setup.
Our Role's structure:
roles/StackStorm.git
└── vars
| └── main.yml
├── tasks
│ └── main.yml
└── handlers
└── main.ymlOur Role Variables:
roles/StackStorm.git
└── vars
└── main.yml
---
# Default GitHub username for private repos
github_username: "dylan-bitovi"
repositories:
- url: "https://{{ github_username }}:{% raw %}{{ st2kv.system.github_token | decrypt_kv }}{% endraw %}@github.com/{{ github_username }}/my_st2_pack.git"
branch: "main"
- url: "https://{{ github_username }}:{% raw %}{{ st2kv.system.github_token | decrypt_kv }}{% endraw %}@github.com/{{ github_username }}/my_st2_jira.git"
branch: "main"git pack config as the playbook runs. An alternate method would be to store the config file in our Role and simply do a file-copy, but that is more rigid in its implementation and makes is a bit more awkward to reference. Using the above method gives us more centralized flexibility in controlling our role schema as it develops and grows. This flexibility is the same reason for parameterizing our github_username, not all of our pack repositories may use the same access and this allows us to set them individually.{{ st2kv.system.github_token | decrypt_kv }} value as Ansible will try to process these Jinja tags, same as StackStorm. Ansible has no knowledge of our ST2 key-value store nor the decrypt_kv function, if we do not escape these tags, our playbook will error out when Ansible processes them. We could escape our {} characters individually, however using the built in {% raw/endraw %} Jinja block tags is a bit more straightforward and easier to read. - url: "https://github.com/StackStorm-Exchange/stackstorm-aws.git"
branch: "main"
Our Role Tasks:
roles/StackStorm.git
├── tasks
└── main.yml
---
- name: Check for 'github_token' environmental variable
fail:
msg: "GitHub token environmental variable is required for the git ansible role."
when: github_token is not defined or github_token is none or github_token|length != 40
- name: Temporarily auth access the data store
become: true
no_log: yes
changed_when: no
command: st2 login {{ st2_auth_username }} -p {{ st2_auth_password }} -l 60
- name: Add GitHub token to ST2 key-value store
become: true
no_log: yes
changed_when: no
command: st2 key set github_token {{ github_token }} --encrypt
- name: Set config info
copy:
dest: "/opt/stackstorm/configs/git.yaml"
content: |
---
repositories:
{% for item in repositories %}
- url: "{{ item.url }}"
branch: "{{ item.branch }}"
{% endfor %}
notify:
- reload st2packconfigs
- restart st2sensors- We verify our
github_token's length for some basic data validation which will be passed in as an environmental variable when we run the Ansible playbook. - We temporarily authenticate with StackStorm utilizing the
-lTTL flag so we can manipulate the encrypted key-value store. We utilize the same variables that the mainStackStorm.st2role uses while configuring the default system user. - We add the
github_tokento the encrypted key-value store, same as the last article, using the same command. - We iteratively build our config file using the values from the
repositorieslist that is present in our/vars/main.ymlfile. - Lastly, we
notifyour two handlers in this Role which perform the same tasks as the previous article to reload the pack config and restart the sensor container to ensure our repos are being monitored.
Our Role Handlers:
roles/StackStorm.git
└── handlers
└── main.yml---
- name: reload st2packconfigs
become: yes
command: st2ctl reload --register-configs
- name: restart st2sensors
become: yes
command: st2ctl restart st2sensorcontainer
tasks/main.yml file as individual actions, but Ansible and ST2's strengths are their flexibility. So by using the handlers, we set ourselves up to more readily being able to reuse commands in other workflows in the future.With our Role in place nestled amongst the other Roles within the
ansible-st2playbook repo that we cloned, all we need to do is modify the main /stackstorm.yml file in the root of playbook repo to let it know about our newly created role, StackStorm.git (modified portion appended):---
- name: Install st2
hosts: all
environment: "{{ st2_proxy_env | default({}) }}"
roles:
- StackStorm.mongodb
- StackStorm.rabbitmq
- StackStorm.st2repo
- StackStorm.st2
- StackStorm.nginx
- StackStorm.st2web
- StackStorm.nodejs
- StackStorm.st2chatops
- StackStorm.st2smoketests
- role: StackStorm.ewc
when: ewc_license is defined and ewc_license is not none and ewc_license | length > 1
- role: StackStorm.ewc_smoketests
when: ewc_license is defined and ewc_license is not none and ewc_license | length > 1
- role: StackStorm.git
when: github_token is defined and github_token is not none and github_token | length > 1git role to the list to be applied to our server.ansible-st2 repo, and we should have a one-line repeatable deployment.github_token variable to be used within our StackStorm.git role: sudo ansible-playbook stackstorm.yml -i 'localhost,' --connection=local \
--extra-vars='st2_auth_username=st2admin st2_auth_password=Ch@ngeMe \
github_token=1cd45ac235e54acbf4aabc09801e0b5abc549afb \
st2_packs=["st2","https://dylan-bitovi:{{ github_token }}@github.com/dylan-bitovi/my_st2_pack.git","https://dylan-bitovi:{{ github_token }}@github.com/dylan-bitovi/my_st2_jira.git"]'
localhost for our Ansible inventory (-i) in this demo but the same power remains here when it comes to passing in a file containing a list of remote hosts to target.st2_auth_username/password here, but to maintain parity with the previous guide, I've re-used the defaults. If we don't set a password the playbook will use the default set in StackStorm.st2/defaults/main.ymlst2 pack:TASK [StackStorm.st2 : Install st2 packs] ************************************
changed: [localhost] => (item=st2)
changed: [localhost] => (item=https://dylan-bitovi:1cd45ac235e54acbf4aabc09801e0b5abc549afb@github.com/dylan-bitovi/my_st2_pack.git)
changed: [localhost] => (item=https://dylan-bitovi:1cd45ac235e54acbf4aabc09801e0b5abc549afb@github.com/dylan-bitovi/my_st2_jira.git)
no_log: yes Ansible tag, however this would mean modifying the related task provided in the base StackStorm.st2 role. There's nothing inherently wrong with modifying the st2 role to suit your own needs, but for demonstration in this article I wanted to leave the ansible-st2 repo as provided.github_token in the key value store at some point in the future without running the playbook, we can do that directly using the same command we used to set the key in the first article.StackStorm.git role, we see our tasks completeTASK [StackStorm.git : Check for 'github_token' environmental variable] **************************************
ok: [localhost]
TASK [StackStorm.git : Temporarily auth access the data store] ***********************************************
ok: [localhost]
TASK [StackStorm.git : Add GitHub token to ST2 key-value store] **********************************************
ok: [localhost]
TASK [StackStorm.git : Add GitHub token to ST2 key-value store] **********************************************
ok: [localhost]
my_st2_jira pack requires jira so naturally it appears here: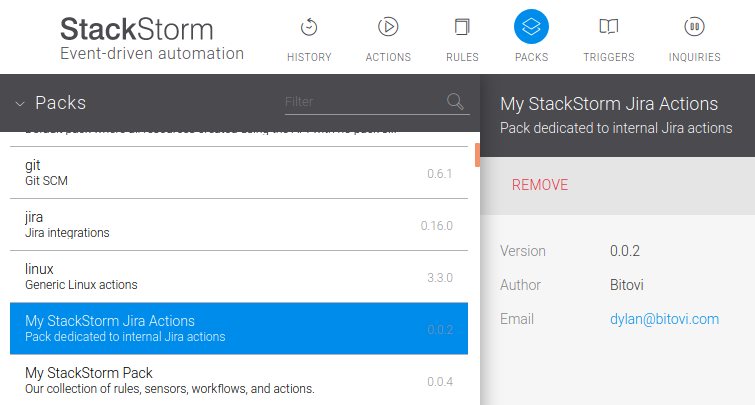
git sensor as it clones the repo's current state: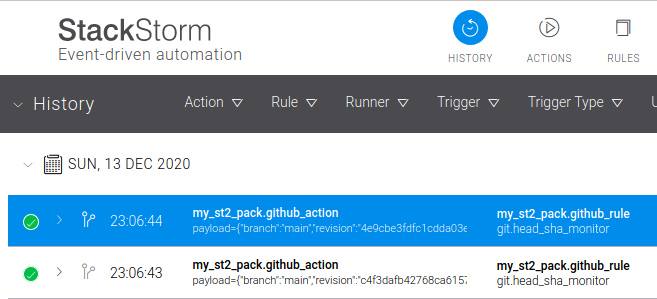
git pack was configured to update on repo changes as it should be: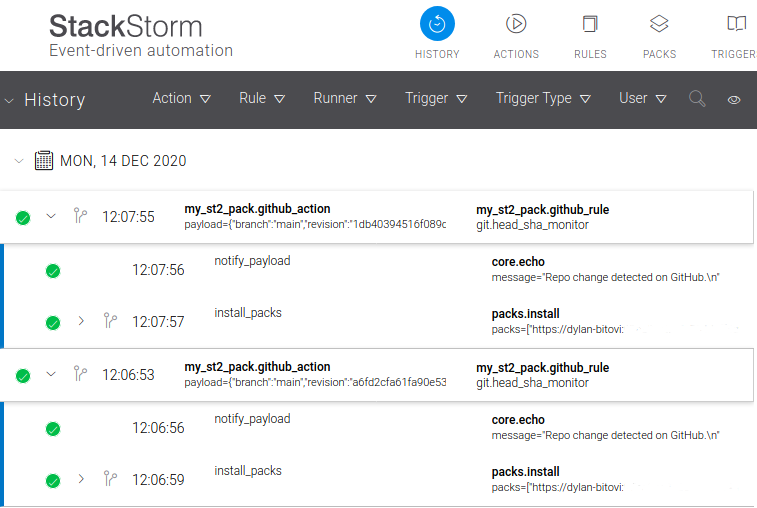
Where to now?
- Clone your internal
ansible-st2playbook repo. - Run the playbook command.
Rightly, in a business organization there would still be some documentation detailing what we've accomplished here. But the internal barrier to entry has been greatly reduced should we want to deploy this at another business unit or with another team.
Using the Ansible playbooks also allows us to look closer into the individual components and features in a way that the one-line install cannot without becoming unwieldy. We now have the power to modify each StackStorm service setup so it can be correctly integrated with whatever unique environment traits your configuration may have and require. A custom st2.conf can be passed in directly if it is so needed.
How can we take this further? I made a sly reference to it earlier in this article with the StackStorm exchange AWS package. Well, what if I told you we can abstract this even further to cover the creation of the Linux server and environment that our instance runs on?
Next stop, the Cloud!
If you have further questions or suggestions, please reach out and become new members in the StackStorm Community Slack, or drop us a message at Bitovi!
Work With Us
We collaborate with development teams on deployment automation, resiliency, observability, and infrastructure migration and management. We’re happy to assist you at any time in your DevOps automation journey!
Click here to get a free consultation on how to tackle your biggest StackStorm problems.

