









.svg)






Welcome to part two of our series about using Temporal to improve the reliability of applications built around Large Language Models (LLM) like the one that powers ChatGPT. Part one explained how to build a Temporal Workflow to process a series of documents and make them accessible to your LLM. This post will show how to develop a Temporal Workflow to find documents relevant to a user’s query and supply them as context to a prompt sent to the LLM using Context Injection. You’ll also learn how Temporal's abstraction will make your application more reliable and make it easier for you to extend it with new features.
Context Injection
Context Injection is one technique in a broad category known as prompt engineering. Because OpenAI’s GPT model is general purpose, you need to provide your LLM with the specific information you want it to reference and include in its responses.
In our example, we want our LLM to be able to provide users with information about Hatchify, a Bitovi open source project. For example, if a user asks, "How do I create a schema where each Todo item belongs to a single user?" we would include all of the documentation related to belongsTo relationships along with the user’s query:
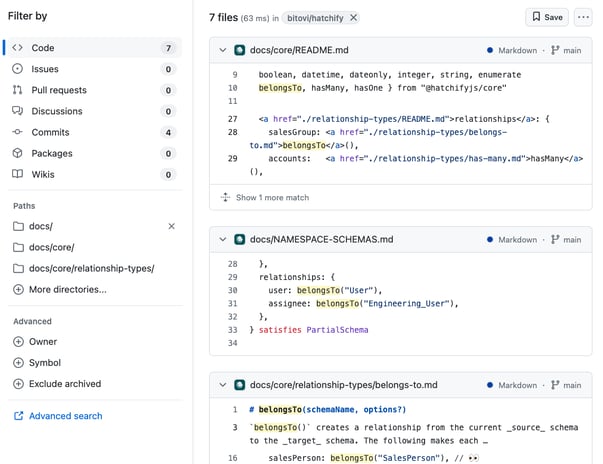
Context Injection Example
This example will compare a user’s prompt to the embeddings created in the previous post, which were generated for the Hatchify documentation. It will then include the most relevant documentation along with the user’s prompt when sending the prompt to the GPT model.
Note: This example is written in TypeScript, but Temporal also supports Python, Go, Java, .NET, and PHP. All of these code samples have been simplified for readability. The complete code can be found on GitHub.
Similar to the first post in the series, starting a Temporal workflow is done through a Temporal client:
const handle = await client.workflow.start(invokePromptWorkflow, {
taskQueue: 'invoke-prompt-queue',
args: [{
query,
latestDocumentProcessingId,
conversationId
}],
workflowId: id
})This starts a Temporal workflow, which will create an S3 bucket for this conversation, generate the prompt, including the relevant documentation, and then invoke the GPT model with the prompt:
export async function invokePromptWorkflow(input: QueryWorkflowInput): Promise<QueryWorkflowOutput> {
const { latestDocumentProcessingId, query } = input
const conversationId = `conversation-${uuid4()}`
await createS3Bucket({ bucket: conversationId })
const { conversationFilename } = await generatePrompt({
query,
latestDocumentProcessingId,
s3Bucket: conversationId
})
const { response } = await invokePrompt({
query,
s3Bucket: conversationId,
conversationFilename
})
return { conversationId, response }
}The generatePrompt activity is responsible for finding documentation related to the user’s query using a similarity search of the embeddings vector data. It filters the query to the latest run of the document processing workflow using the latestDocumentProcessingId input parameter. It then stores the documentation in a JSON file in the S3 bucket so it can be used in the subsequent Activity:
export async function generatePrompt(input: GetRelatedDocumentsInput): Promise<GetRelatedDocumentsOutput> {
const { query, latestDocumentProcessingId, s3Bucket } = input
const pgVectorStore = await getPGVectorStore()
const results = await pgVectorStore.similaritySearch(query, 5, {
workflowId: latestDocumentProcessingId
});
const conversationFilename = 'related-documentation.json'
putS3Object({
bucket: s3Bucket,
key: conversationFilename,
body: Buffer.from(JSON.stringify({
context: results
}))
})
return {
conversationFilename
}
}The invokePrompt activity pulls the file from S3 and then invokes a GPT model using langchain with the query :
export async function invokePrompt(input: InvokePromptInput): Promise<InvokePromptOutput> {
const { query, s3Bucket, conversationFilename } = input
const conversationResponse = await getS3Object({
bucket: s3Bucket,
key: conversationFilename
})
const conversationContext = await conversationResponse.Body?.transformToString()
let relevantDocumentation: string[] = []
if (conversationContext) {
const documentation: { context: Document<Record<string, any>>[] } = JSON.parse(conversationContext)
relevantDocumentation = documentation.context.map(({ pageContent }) => pageContent)
}
const gptModel = new ChatOpenAI({
openAIApiKey: OPENAI_API_KEY,
temperature: 0,
modelName: 'gpt-3.5-turbo'
})
const response = await gptModel.invoke([
[ 'system', 'You are a friendly, helpful software assistant. Your goal is to help users write CRUD-based software applications using the Hatchify open source project in TypeScript.' ],
[ 'system', 'You should respond in short paragraphs, using Markdown formatting, separated with two newlines to keep your responses easily readable.' ],
[ 'system', `Here is the documentation that is relevant to the user's query:` + relevantDocumentation.join('\n\n') ],
['human', query]
])
return {
response: response.content.toString()
}
}Invoking the query, "How do I create a schema for todo list items where each item belongs to one person?" returns the output from the GPT model, including the relevant details found in the Hatchify Documentation. 🎉
To create a schema for a todo list item where each item belongs to one person, you can define the schema using the `belongsTo` relationship in the Hatchify open-source project in TypeScript. Here's an example of how you can define the schema for a Todo item that belongs to a User:
```typescript
import { belongsTo, string } from "@hatchifyjs/core";
import type { PartialSchema } from "@hatchifyjs/core";
export const Todo = {
name: "Todo",
attributes: {
name: string({ required: true }),
description: string(),
dueDate: dateonly(),
},
relationships: {
user: belongsTo("User"), // Defines the relationship where each Todo belongs to one User
},
} satisfies PartialSchema;
export const User = {
name: "User",
attributes: {
name: string({ required: true }),
email: string(),
},
relationships: {
todos: hasMany("Todo"), // Defines the relationship where each User can have many Todos
},
} satisfies PartialSchema;
```
In this example, the `Todo` schema has a `user` relationship defined using `belongsTo("User")`, indicating that each Todo item belongs to one User. The `User` schema, on the other hand, has a `todos` relationship defined using `hasMany("Todo")`, indicating that each User can have many Todo items.n' +
You can further customize the attributes and relationships based on your specific requirements.Benefits of Using Temporal for Your LLM
Using Temporal’s Durable Execution abstraction for this use case has similar benefits to using it for the Document Processing pipeline of the previous example: the workflow can never unintentionally fail. It can run for as long as necessary. The independent nature of Activities also makes it very easy to extend the application’s functionality without creating overly complex code.
1. Your Workflow Can’t Fail
Durable Execution with Temporal means that your application is resilient to all types of failures that can happen when building a system like this. If OpenAI is down or your application is rate-limited for any reason, Temporal will continue to retry your Activities until they complete successfully. If your database goes down or your application server crashes, Temporal will continue your workflows right where they left off when they start back up. Temporal also gives you the flexibility to configure these retry policies in any way you need to suit your application’s needs.
2. Your Workflow Can Run Forever
Similar to failures, LLM-based applications can sometimes be slow. Requests to LLMs can be quite time-consuming, especially when generating a large text response. With Temporal, your Workflow can run as long as needed.
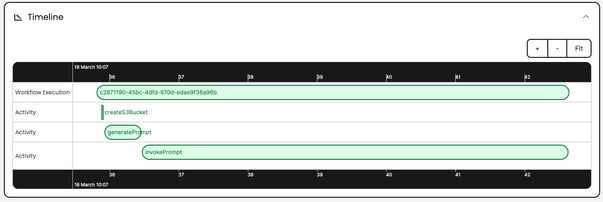
It is also a breeze to support status indicators and completion percentages using Temporal Queries so you can let your users know how far along their requests are.
3. Your Prompt Engineering is Easily Extensible
Context Injection and Prompt Engineering techniques are constantly growing. Building your application around Temporal makes it easier for your application to grow along with your LLM. Activities are naturally independent and easily scalable, allowing you to quickly add new features and constantly improve your application. Techniques that would otherwise be very complex to build within a distributed, scalable system, such as chaining multiple prompts and responses together to form a coherent conversation, are trivial when built within a single Temporal Workflow with independent Activities.
Temporal also provides APIs such as signalWithStart so that a single workflow can queue multiple messages from the end user in order to handle them with a single response. There are also many ways to synchronize multiple workflows, so you don’t run into contention issues when multiple concurrent workflows need access to the same resources, such as a database or another external system.
Summary
Concluding our series on making applications powered by Large Language Models (LLMs) more reliable with Temporal, we're diving into a crucial aspect: injecting context and engineering prompts. While our previous installment focused on processing documents, here, we're all about finding the perfect documents for user queries and seamlessly integrating them into LLM responses. And guess what? Temporal makes it all feel like a breeze, adding reliability and future-proofing to your app.
With context injection, we're not just enhancing user queries; we're making LLMs smarter and responses more tailored. Picture Temporal as your trusty sidekick, ensuring your app never misses a beat. From handling pesky API downtimes to seamlessly scaling with your ambitions, Temporal's got your back. Plus, with its infinite runtime magic, even the most demanding tasks feel like a walk in the park. So, if you're ready to infuse your LLM-powered app with reliability and a sprinkle of magic, join the Temporal party—it's where innovation meets peace of mind!
Need more help with Temporal?
Bitovi has your back! Our friendly team of Temporal Consulting experts would happily walk you through any step of your orchestration. Schedule a free consultation to get started.

![Your LLM Should Be Built on Temporal [Part 1: Document Processing]](https://www.bitovi.com/hs-fs/hubfs/LLM-1.png?height=117&name=LLM-1.png)
