









.svg)






Taking advantage of the burgeoning AI trend, many of today's applications are built around AI tools like ChatGPT and other Large Language Models (LLMs). AI-optimized applications often have complex software pipelines for collecting and processing data with the LLM. Temporal provides an abstraction that can significantly simplify data pipelines, making them more reliable and accessible to develop. In this post, you’ll discover why you should use Temporal to build applications around LLMs.
Document Processing Pipelines
Large Language Models excel at answering general-purpose questions using public information from the Internet. However, when serving as the basis of your product, LLMs must provide accurate and up-to-date information about your business. Techniques like Prompt Engineering, Embeddings, and Context Injection allow LLMs to provide the exact information you want them to reference and explain to your users.
While context window size for most LLMs is trending upward, allowing more and more information to be provided as part of a prompt, LLM pricing often means that the larger your prompts, the more expensive each request becomes. Creating a “pipeline” to collect and prepare your data to provide only the information you want the LLM to reference will make your application much less expensive and more performant.
Document Processing Pipeline Example
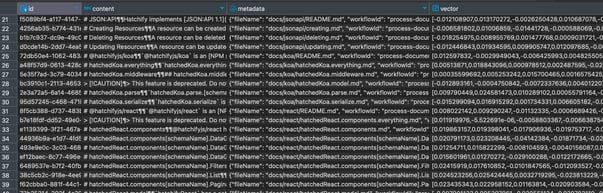
The example below shows how to generate Embeddings for a set of documents. Embeddings are numerical representations of text that can be used to find which documents are most similar to a user’s query. This allows you to inject only the most relevant information into your prompts.
This example uses Langchain and OpenAI’s text-embedding-ada-002 embeddings model, but many other options are available if this doesn’t suit your application’s needs. This is just one example of something a pipeline could be used for. The techniques in this article are general purpose and are useful for applications built around LLMs, Semantic Search, Retrieval-augmented Generation, and many other AI technologies.
The code in this example will collect and process all of the markdown files from the docs/ folder of the GitHub repository for Hatchify, a Bitovi open-source project. Starting a Temporal workflow is done through a Temporal client:
Note: This is written in TypeScript, but Temporal also supports Python, Go, Java, .NET, and PHP. All of these code samples have been simplified for readability. The full code can be found on GitHub.
const id = `index-workflow-${nanoid()}`.toLowerCase().replaceAll('_', '')
const handle = await client.workflow.start(documentsProcessingWorkflow, {
taskQueue: 'documents-processing-queue',
args: [{
id,
repository: {
url: 'https://github.com/bitovi/hatchify.git',
branch: 'main',
path: 'docs',
fileExtensions: ['md']
}
}],
workflowId: id
});The code above starts the Temporal Workflow for the pipeline, executing the code in the example below. The Workflow code creates an S3 bucket for temporary storage, collects all of the documents, processes the documents and stores the embeddings data as vectors in Postgres, and then deletes the temporary S3 bucket:
export async function documentsProcessingWorkflow(input: DocumentsProcessingWorkflowInput): Promise<DocumentsProcessingWorkflowOutput> {
await createS3Bucket({ bucket: id })
const { zipFileName } = await collectDocuments({ ... });
const { collection } = await processDocuments({ ... })
await deleteS3Object({ bucket: id, key: zipFileName })
await deleteS3Bucket({ bucket: id })
return { collection }
}Each of these functions is a Temporal Activity, which means that Temporal adds some additional functionality, which we’ll explain in the next section, but they are written as completely normal TypeScript functions. Here is the collectDocuments Activity:
Note: This is an embedded Gist to ensure the code displays in its entirety.
Similarly, the processDocuments Activity is another normal TypeScript function:
export async function processDocuments(input: ProcessDocumentsInput): Promise<ProcessDocumentsOutput> {
const response = await getS3Object({
bucket: s3Bucket,
key: zipFileName
})
fs.writeFileSync(zipFileName, await response.Body.transformToByteArray())
await extractZip(zipFileName, { dir: path.resolve(temporaryDirectory) })
const embeddingsModel = new OpenAIEmbeddings({
openAIApiKey: OPENAI_API_KEY,
batchSize: 512,
modelName: 'text-embedding-ada-002'
})
const pgvectorStore = await PGVectorStore.initialize(
embeddingsModel,
config
)
filteredFileList.forEach(async ({ fileName: string, fileContent: string }) => {
await pgvectorStore.addDocuments([{
pageContent: fileContent,
metadata: { fileName, workflowId }
}])
})
pgvectorStore.end()
return {
tableName
}
}And there you have it — all of the code required for this pipeline to collect and process the documents from this GitHub repository and store them as embeddings within a Postgres database.
Benefits of Using Temporal for Document Processing
Temporal is an abstraction that delivers Durable Execution, which means that Temporal Workflows can never unintentionally fail and can run for as long as needed, without needing to store the state of execution outside of the function.
1. Your Pipeline Can’t Fail
Traditionally, code like this pipeline is very error prone. All of the steps involved are prone to failure:
-
Pulling documents from external systems
-
Third-party APIs
-
Long-running data processing
-
Bulk-storing data to a database
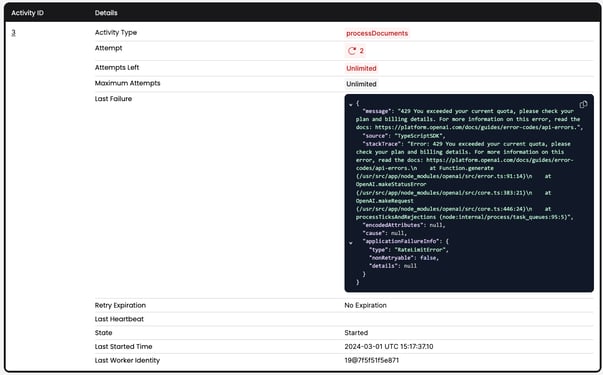
Writing these as Temporal Activities means that Temporal will automatically retry any failures and also handle timeouts for anything that runs for too long. All of this is configurable, but Temporal provides some sane defaults. For example, if the OpenAI request is rate limited (or you forget to add a credit card 😂), the request will be automatically retried until it is successful.
2. Your Pipeline Can Run Forever
Operations like generating embeddings for a large number of documents can be quite time-consuming. This is not an issue with Temporal, as the Workflow execution has no time-limit. Even if processes or servers crash, your Workflows will continue exactly where they left off prior to the crash.

3. Your Pipeline is Scalable
This example only has 50 or so documents that need to be processed, but a pipeline for thousands or millions of documents could be handled just as quickly. Temporal supports child workflows, so this pipeline could easily fan out per repository, or per folder, or per file type with separate workflows for each. You could also have an Activity responsible for generating the list of documents and then fan out to child workflows for every 100 documents (for example):
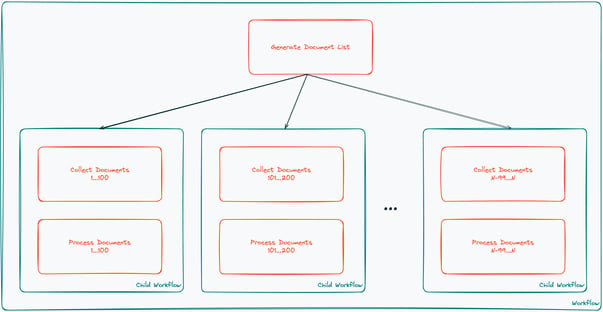
The possibilities for scaling are endless so it can easily be suited the pipeline’s use-case.
Summary
With the surge in demand for AI applications, it's crucial to streamline data pipelines, especially when using powerful tools like Large Language Models (LLMs). This is where Temporal steps in as a game-changer, simplifying these pipelines and making them more reliable and user-friendly. By embracing Temporal, you can effortlessly manage document processing workflows, ensuring accuracy, efficiency, and affordability in AI-powered apps.
Temporal's Durable Execution ensures that workflows persist even in the face of potential hiccups. Plus, its infinite runtime capability means you can tackle large datasets without sacrificing scalability. By using Temporal for your document processing pipelines, you can fine-tune performance and maintain affordability. So, why not unlock a world of seamless AI integration and innovation with Temporal?
Note: Don't miss part two of our series on prompt engineering!
Need help executing your Temporal vision?
We can help! Our friendly team of Temporal Consulting experts would be happy to walk you through any step of your orchestration. Schedule a free consultation to get started.

