




.svg)






- Alleviating some of the burdens of Site Reliability Engineers (SREs)
- Minimizing the risks of human error
- Ensuring proper communication and visibility around issues when they arose in a way that could scale efficiently as the infrastructure grows.
Let’s investigate these problems in-depth and see how DevOps automation with StackStorm helped SREs automate common tasks, minimize downtime, and sleep easier in a scalable, reliable, and fully customizable way.
1. The Burdens of SRE’s
As with many companies, the client’s Site Reliability Engineers (SREs) were manually investigating and resolving DevOps issues. They would get notified of an alert at any time of day, log in to disconnected systems and interfaces to gather information about the issue, and then take actions to remediate the issue, which are often tedious and repetitive or complicated.
Heavy training is required for a person with these responsibilities. Even the most competent SRE is human and, therefore, prone to error - especially if an alert requires them to wake from a deep sleep in the middle of the night.
Additionally, the process of an SRE investigating any alert takes a lot of valuable time, during which the end user is forced to wait until the issue is resolved.
With all of the above issues, infrastructure growth is extremely difficult because with growth comes complexity, and the effort required for SREs to understand, diagnose, and remediate issues increases as well.
2. Communication is Difficult
The client has many systems that need to communicate with one another, and since they don't always play well together, the burdens of SREs are compounded by the increasing complexity and the risk of human error.
Additionally, most of the communication mechanisms were either fragmented or duplicated across systems. In other words, either
- Every system did things its own way
- Or one system would duplicate code from another rather than use a common interface or library
For example, one team’s application might have a custom python library to send requests to a bug reporting system, but another team might write their own bash script or even a different python library to make the same requests instead of using a common library or interface.
3. Lack of Visibility
Along with manual intervention by an SRE and fragmented system-to-system communication comes a distinct lack of visibility into what is going on across systems. Many systems record metrics important for remediating issues such as memory usage, process health, and event logs, but they are often vague or ambiguous without data from another system. There was no way to correlate an error in one place to an event in another without rigorous investigation, and SREs must manually slog through various error logs and historical data across various software systems in order to get to the bottom of an issue, which only gets more complex and time-consuming as more software and services are added to the infrastructure.
For example, SystemA might encounter an error that affects SystemB, but SystemA sends error information to a central logging system such as Splunk where SystemB simply logs errors to standard output. In order to understand the full scope of the issue, an SRE would need to sign in to Splunk, run a specialized query to extract log data for SystemA, SSH into SystemB, read the logs, and manually correlate the information.
Often, high-level insights and patterns are lost as data is fragmented across systems.
Using StackStorm to address these problems
To address these problems, we integrated StackStorm and trained teams to use it effectively.
The company’s requirements for a solution included scalability, reliability, a pluggable architecture, complex workflow creation, and customer support. After reviewing several options (such as Rundeck), we found StackStorm to be best suited for the task because it was able to meet and exceed all the requirements above.
StackStorm
StackStorm is an event driven automation platform. It's a robust engine for IFTTT (If This Then That) for DevOps.

StackStorm accomplishes event driven automation through the simple concept of a Pack, which contains four basic parts: Triggers, Rules, Actions, and Workflows. Basically, a Rule says “IF This Trigger happens, Then execute That Action or Workflow, a set of actions”.
This simple concept is extremely powerful and allows StackStorm to be useful in many areas including Assisted Troubleshooting, Auto Remediation, IT Process Integration, Continuous Integration and Deployment, Chatops, and even integration with Internet of Things devices.
In this client's case, StackStorm integration provides automatic remediation workflows across systems all in one place – and their SRE's are able to sleep through the night.
Diagnosis & Remediation
To solve the company’s problems described above, we initially focused on Assisted Troubleshooting and Auto Remediation.
The company already had monitoring systems integrated into their infrastructures and these monitors would be configured to send an alert when metrics in a system exceed a threshold.
Instead of the alert being sent to an SRE’s email, we set up Webhook Rules in StackStorm which triggered diagnostic workflows.
The diagnostic workflow would, for example, query logs in a logging service, ping the affected systems for health or status, notify a chat room of the investigation’s progress, prepare a succinct remediation procedure, and notify an SRE of all the results.
There was also a corresponding remediation workflow which would be given information from the diagnosis and take action. To continue the above example, it would take log information and health status for a given server and, if the server was unhealthy, force a restart on the server via a StackStorm Action built with Python.
Through workflows, the remediation could easily be combined with the diagnosis so that if the diagnosis revealed that an action needed to be taken, it could simply perform the remediation without any intervention from an SRE.
Infrastructure Setup
In addition to the basic use of StackStorm to solve the immediate problem, we set up infrastructure and processes for the company to ensure that StackStorm remains a long-term, integrated remediation solution.
As a critical hub for lots of events, it was very important that StackStorm always be available.
StackStorm’s microservices can easily be separated out onto their own scalable clusters, and, for this client, it was installed in a High Availability setup across multiple environments like QA and Production.
Pack Development & Training
Teams in the company were trained on pack development to write integrations with their services via python actions, rules, and triggers and craft diagnostic and remediation workflows for their use cases.
We created and provided a framework and documentation for local pack development via Docker as well as a clear path to get their packs from their local machine to an internal, client-specific Pack Exchange, a place to host packs similar to the StackStorm Exchange, and then out to QA and Production environments.
Since the pack development path was well defined and flowed through the source control management platform, git, teams could take advantage of additional development practices such as code reviews, and pack deployments to StackStorm could be automatically managed by StackStorm itself. This means that pack developers simply push pack code to GitHub, and StackStorm will install the latest version of the pack automatically. Cool, right?
Custom UI
To augment the team's interactions with StackStorm with functionality specific to the company, we designed and built a React-based User Interface that communicated with StackStorm via its robust REST API.
The interface features multi-team organizational features, advanced rule creation, and integration with the client’s AuthN and AuthZ mechanisms.
Additionally, with StackStorm and our custom UI as the hub for many teams and systems, we could easily aggregate the vast amounts of, sometimes disparate, data into a reporting dashboard to gain valuable insight into the events being triggered across the company.
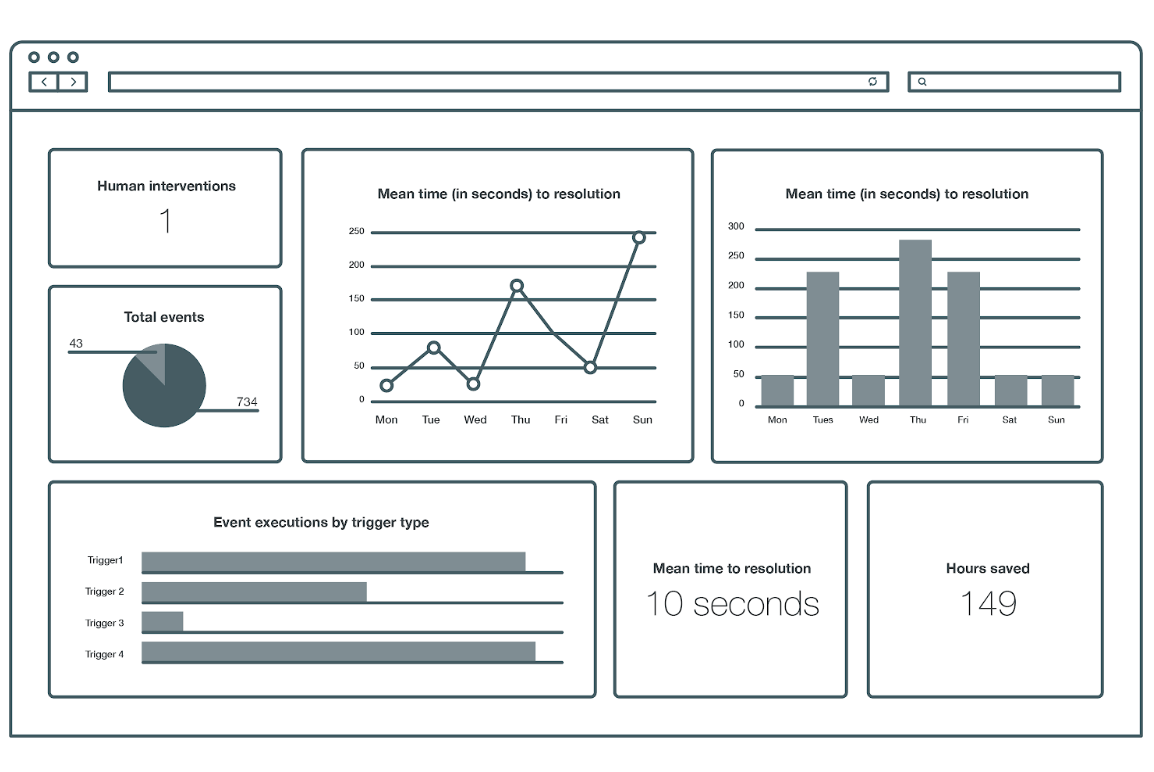
Diagnosing the results
We were able to greatly reduce SRE fatigue, training costs, incident resolution errors, and incident resolution time by using StackStorm to automatically recognize common DevOps issues.
Communication across disparate systems and teams was streamlined and consolidated to increase the overall efficiency of teams in the company.
With the augmentation of the customized user interface, we were able to provide valuable insight into the behaviors of various interconnected systems as well as a streamlined user experience that corresponded to the company’s internal strategies.
Are you a high-growth company looking to address the challenges of a complex, scalable infrastructure? Bitovi can help you get started with StackStorm. Learn more here.