









.svg)






It cannot be emphasized enough—the structural model of your data will set the foundation for the rest of your app.
Sometimes we spend so much time focusing on the next great library, utility, or framework that we forget foundational principles that have a huge financial impact on our company. Understanding database normalization will save your company money, and save
your team from future headaches.
In this post, we’ll focus on database normalization, which is a set of guidelines and processes for optimizing a database for efficient storage and long-term maintenance. If you’re a backend developer, this post will either be a short review of something you already know and apply, or it will be vital information for your career going forward. If you’re a frontend developer, you’ll potentially save yourself a lot of delays and frustration by being able to identify when these rules are being ignored.
An unsupportive data structure can leave a frontend team in limbo for weeks while data-level problems are addressed. So no matter which part of the app you work on, you may be able to save yourself the hassles that come from implementing poor data structure. Let’s dive in!
Who Invented Database Normalization?

Database normalization was invented by the same people who worked on the Relational Data Model. While working at IBM, Edgar F. Codd created his “Relational Data Model”. It was very “mathy”.

Codd’s model was so mathematical that Todd Chamberlain and Raymond F. Boyce, also working at IBM, were tasked with making Codd’s work easier to use. They came up with what they called the “Structured English Query Language,” which was originally abbreviated as “SEQUEL”, and later became SQL, for short. But how is it pronounced?

Plenty of discussions have centered around how to pronounce “SQL,” based its history, it’s ok to pronounce it “Sequel” or “S.Q.L.”, but please don’t ever pronounce it “squeal”.
Why Database Normalization?
So now that we’ve seen a brief history of SQL and how to pronounce it, let’s get to the “why” of database normalization. Since we all crave acronyms on a daily basis, let’s go over some. These will likely be very familiar.
- DRY - stands for “Don’t Repeat Yourself”
- KISS - stands for “Keep It So Simple”
- BPDSCCALOPAFMOOYC (pronounced “Bi-Ped-Scalopa-Fa-Moo-Yuck”) - stands for “Because Poor Database Structure Can Cause A Lot Of Problems And Funnel Money Out Of Your Company.” It’s not as well-known, but it’s 100% real.
The rules of database normalization all come down to efficiency. They might as well be called the rules of efficiency. Any time you break one of the rules, you’re pretty much guaranteeing a loss in efficiency, which will undoubtedly have a financial impact.
What Does Normalization Look Like?
To illustrate how database normalization works, we’re going to use this dataset. Earlier this year, a new client came to us because their application stopped working. The third-party year/make/model API they were using forgot to pay its hosting bill. The service shut down on Friday night, which ended up costing this company a good sum of money over the weekend. We were able to use this dataset to quickly build the year/make/model API directly into their application. Here’s what the dataset looks like in spreadsheet format:
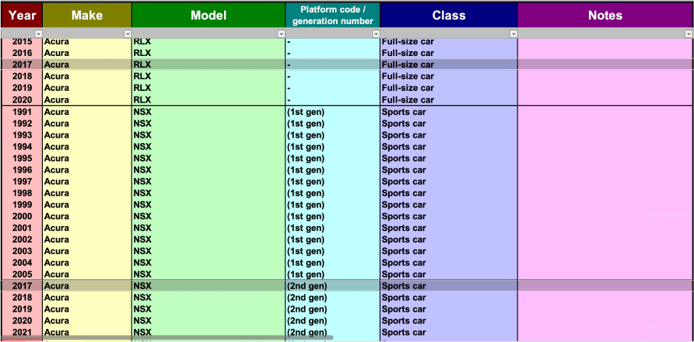
No surprises, it looks just like a typical spreadsheet. There is a lot of repetition from row to row in nearly every column. To normalize this data, we’ll end up splitting one table into multiple, as shown here:
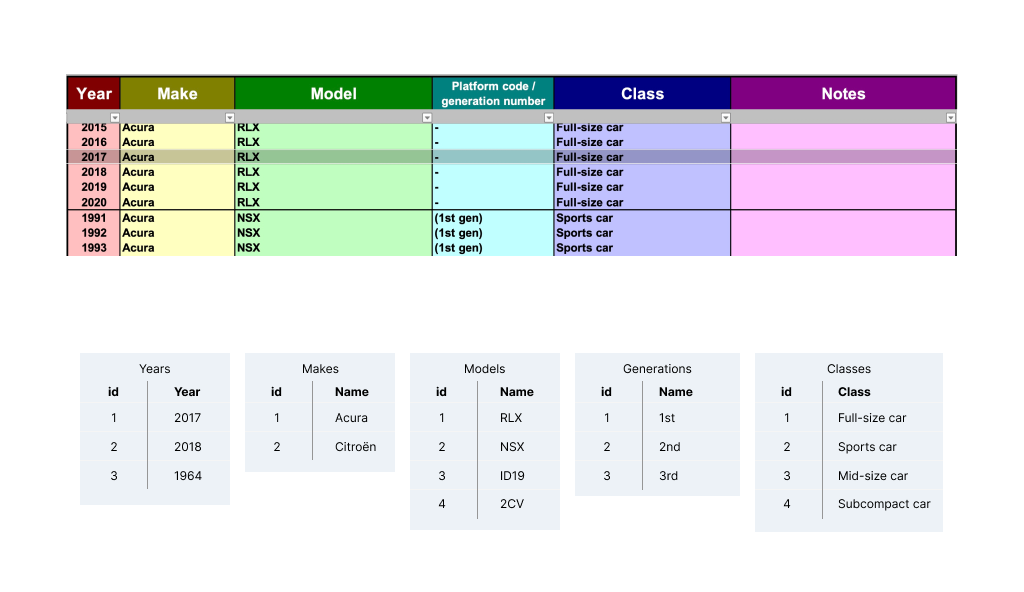
Now let’s go over the rules that make it easier to know how to split up our database. It’s time to go over the Normal Forms.
Normalization Standards
Normal Forms are the rules that tell us how to organize our data to be more efficient. In general, there are seven normal forms ranging from 1NF to 6NF. There’s an unnumbered one in the middle called Boyce-Codd Normal Form, which is considered an extension of 3NF. This article only illustrates the first three.
Let’s see how our data changes as we apply each normal form to the original data set. You’ll notice that each normal form is considered to include all of the normal forms that precede it. So 2NF assumes 1NF is already applied. And 3NF assumes that 2NF and 1NF are already applied. Now, let’s see how our data changes with 1NF.
First Normal Form - 1NF
First normal form, called 1NF for short, says that we need to simplify complex attributes. This usually means multiple values under a single attribute. Our particular dataset doesn’t have any complex attributes, but if we imagine that it’s possible for a vehicle to belong to multiple generations, applying 1NF to that data would look like this:

Notice how we took the 2nd and 3rd generation values and spread them into two rows. The result is that we have two rows whose values all match except for the generation column.
Second Normal Form - 2NF
Second Normal Form assumes that we’ve already applied 1NF, so there are no remaining complex attributes. For a dataset to be in Second Normal Form, it means that every row in the table has been given a primary key:
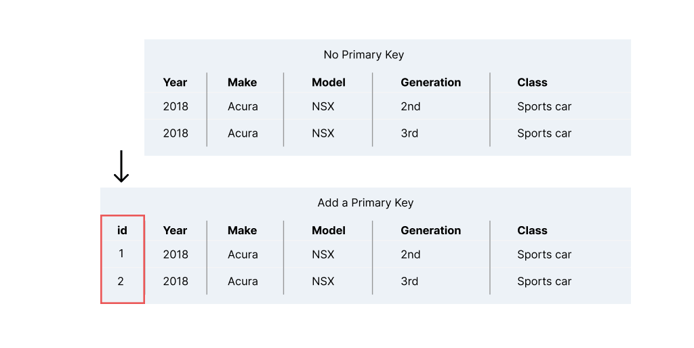
The above example shows adding an integer as the primary key.
Note: If there’s a chance that your table will contain more than 2.1 billion rows, you might want to use a BigInt data type OR using UUIDs to avoid the upper limit of auto-incrementing integers. A BigInt can count up to 9,223,372,036,854,775,807.
Second Normal Form is the most-commonly violated rule of relational data normalization. Sometimes database developers think it’s smart to make a compound key (one that’s made of multiple existing columns) be the primary key. In each scenario where I’ve encountered creative license for primary keys, I’ve seen zero benefit and lots of wasted time. Do everyone a favor and dedicate a single column to the primary key. Keep it simple.
Third Normal Form - 3NF
Like 2NF, Third Normal Form assumes that the data already complies with 1NF and 2NF. The focus of 3NF is to eliminate “Transitive Dependencies” in your data’s structure. So what is a transitive dependency? In the case of databases, “transitive” can be understood as “implied.” For example, if a>b and b>c then a>c. While there’s not a direct relationship between the records, there is a relationship in their function.
We’re dealing with computer science, so think of transitive like you would the transitive law of mathematics. There’s an implied relationship between a and c. To find transitive dependencies in our data, we need to look for implied relationships. Let’s start by looking at Acura in the data:

Acura in both rows has the same intended meaning. We're talking about the Make of two different cars. If we changed only one of them to Honda, it ruins the integrity of the original meaning.
One way to identify a transitive dependency is to find any place where you have to make more than one edit in order to fully change meaning. In this case, we’d have to change each individual instance of Acura across the database.
So now that we know that Acura is a transitive dependency, we can also know that any other duplicate value under Make is also a transitive dependency. The most exciting moment of relational data has just arrived: we get to create our first relational table! Here's how it looks:
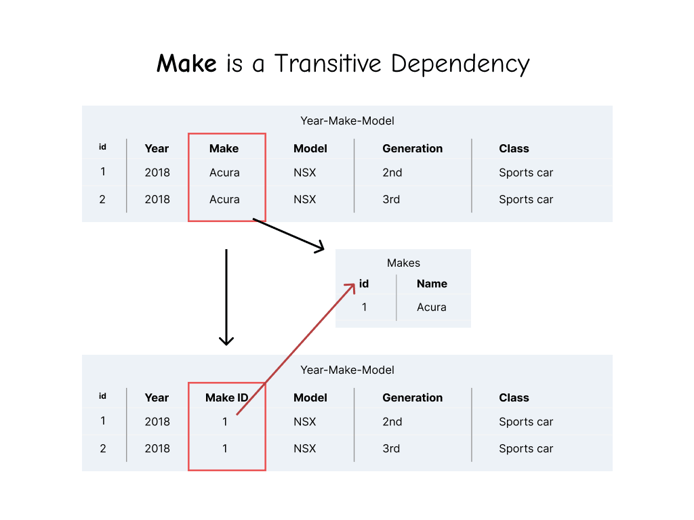
To eliminate the transitive dependency on Make, we created a Makes table and moved every unique value to the table. We then gave each record its own id to immediately put the the table into 2NF. Finally, in the original table, we created a Make ID column and referenced each primary key from the new Makes table. So, again, those steps are:
- Make a new table that includes columns for all values that belong with the original data, in this case
Name. - Give the table a primary key, in this case
id. Now the table is in 2NF. - Put only unique values in the new table. Now the new table is in 3NF.
- Add a foreign key column to the original table, in this case
Make ID - Reference each original value by putting its corresponding primary key into the
Make IDcolumn.
Let’s keep identifying transitive dependencies in our original table.
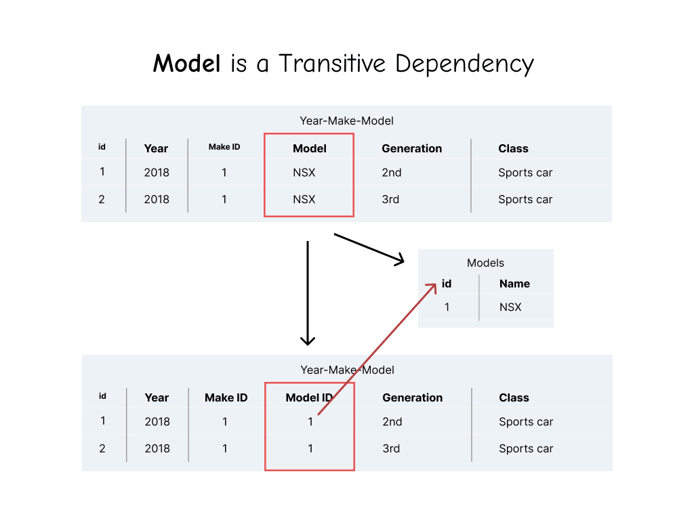
Since Model is a transitive dependency, it gets the same treatment as Makes. We can follow the same 5 steps as mentioned above.
Now the next one might be more difficult to spot. Is Generation a transitive dependency?
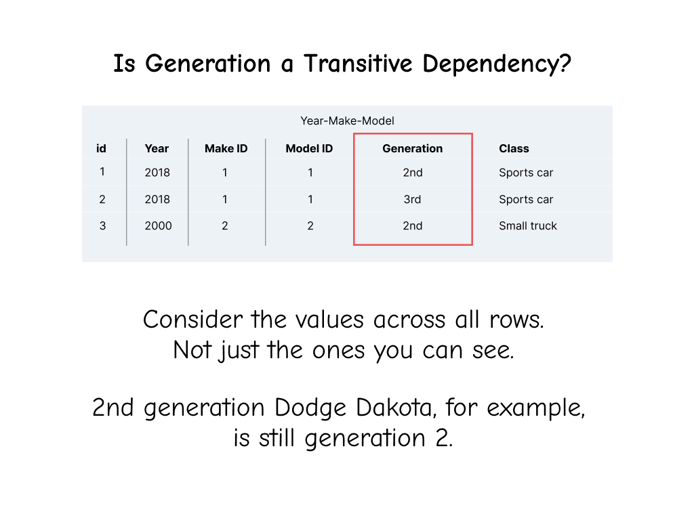
When considering if some data is a transitive dependency, you need to consider the values in all of the rows, including ones you don’t currently see. If we expanded our view a bit, we would see multiple values for each generation. Even though you can’t see it in the examples, this is a database of all vehicle makes and models, so there’s a 2nd generation Dodge Dakota and a 2nd generation Acura NSX. So Generation is a transitive dependency. Let’s give it the same treatment:
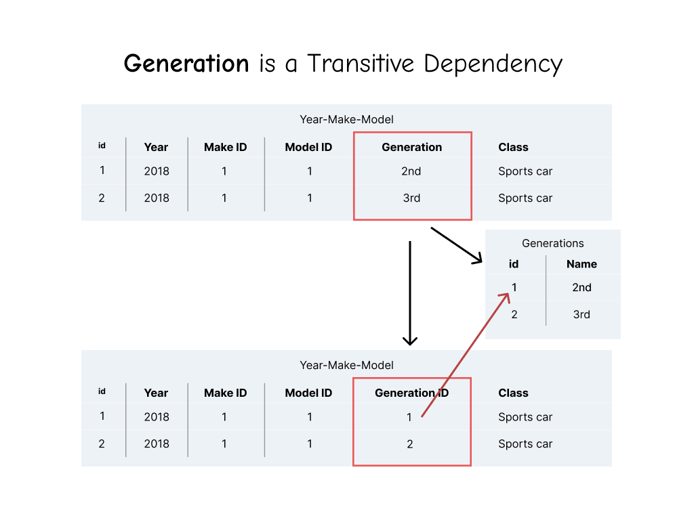
Class is transitive, so the same steps apply:
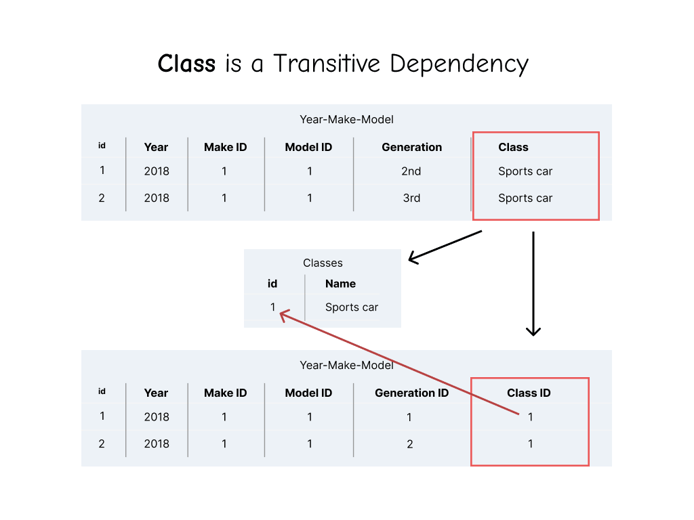
And finally, Year is transitive, so it gets its own table, as well:

Normalization: Before and After
So let’s take a look at before and after applying Third Normal Form:

We ended up with six tables. It might not look visually efficient, but under the hood it takes up less space and is very efficient to change any given value. For example, if we want to change row 1 in the Makes table and rename every Acura to Honda, we only have to change that single cell. There's only one change to be made because we put the data into Third Normal Form and got rid of all transitive dependencies. Let's see what Smiling Einstein has to say about it.

Summary
If you know the results of database normalization done correctly, you’ll agree with Smiling Einstein. The terrific benefits include:
- Simpler data changes, leading to time better spent for members of all our teams.
- More efficient data storage, leading to smaller data storage bills and maybe even data egress bills.
- Full avoidance of problems related to BPDSCCALOPAFMOOYC (“Bi-Ped-Scalopa-Fa-Moo-Yuck”) Leading to money not funneling out of your company.
The changes will ripple throughout your organization. With knowledge of all of this avoided opportunity cost, maybe it’s time to read all of Bitovi’s soft skills blog posts and convince management that it’s time for the Data Engineers to get a raise. 😉
Looking for a SQL Sequel?
Bitovi has expert backend consultants ready to dive in and assist you with your project! Schedule a free consultation to get started.

