









.svg)






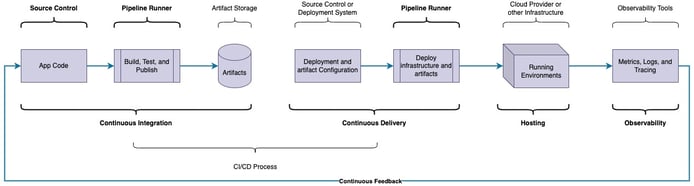
Continuous Integration (CI) automations are a vital part of DevOps and Cloud Engineering that simplify software delivery by helping ensure all code deployed to a hosted environment is bug-free and secure.
For your team to implement Continuous Delivery for your software, you’ll need to understand the role that Continuous Integration plays in the Continuous Delivery process.
Continue reading to learn more about Continuous Integration!
|
On this page:
|
Why is Continuous Integration Needed?
Continuous Integration standardizes the build, test, and publish processes for any number of developers, which helps to lower discrepancies across developer and hosted environments. Each developer must take fewer steps to deliver software due to CI automation.
For the Continuous Delivery process to be truly viable, a pattern of “build once, deploy anywhere” should be adopted. This pattern means that artifacts published from code changes can be confidently deployed in any environment, including Production, because they have been thoroughly tested and audited.
What is Continuous Integration?
Continuous Integration is the automated process that ensures that application code is deliverable to a hosted environment quickly and securely. The intention is to take the changed source and create a secure, deployable artifact.
The core functions of Continuous Integration are: Build, Test, and Publish.
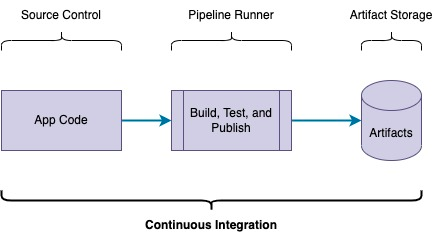
Building and Testing can often occur in parallel, depending on the test type, and it’s common to run some tests before a build and others afterward. Publishing, however, needs to happen after all tests and builds have been completed satisfactorily.
Build
Applications or services often need to run a build process to produce a deployable artifact. Build artifacts will vary depending on service type or programming language. Some build artifacts include:
-
NPM Packages
-
Docker Images
-
Executable Binaries
-
Zip files
The build process should run any time changes in code need to be deployed to an environment.
Test
Automated tests are used to ensure that code is bug-free. They’re arguably the most critical component of Continuous Delivery because it’s challenging to know if a deployment will break an environment if the code being deployed has not been rigorously tested.
Testing can come in many forms. Some examples of tests include:
-
Unit Tests
-
Functional Tests
-
Integration Tests
-
Smoke Tests
-
End-to-End Tests
-
Compliance Checks
-
Code Quality Checks
-
Security Checks
Which tests are implemented and executed and the definitions of many tests will vary by company, team, and project. There is often an overlap of functionality between multiple test types. Some test types, such as end-to-end tests, are executed not at Continuous Integration time but after a deployment. While other test types, such as security checks, can happen at Continuous Integration time and post-deployment.
Regardless of the definitions, it is important to test things like:
-
Individual functions or functionality
-
How functions interact with other functions
-
How services interact with data
-
How services interact with other services
-
How all services work together with real (or real-ish) data
-
Quality of the code
-
Security of the code
If you’re not prioritizing tests, you should absolutely start, especially if you’re moving towards Continuous Delivery for your software.
Publish
Once code changes have been built and thoroughly tested, the build artifacts are ready to be stored for deployment. The publishing process takes built artifacts and hosts them in a location that is accessible to the deployment process or deployed environments.
There are several categories of artifact repositories to store published artifacts: All-in-one, Software Suites, Specific, and Generic.
All-in-one
Some all-in-one artifact repositories include:
JFrog Artifactory and Sonatype Nexus Repository are stand-alone artifact repositories that support most types of artifacts your team might need to deploy. Both JFrog and Nexus Repository have free Open Source Software versions if you want to host one of the solutions yourself and have the means to manage it. JFrog has a limited free tier, and both JFrog and Nexus Repository have tiered paid versions for enhanced features and should be considered if your team(s) have many types of artifacts to publish or want to utilize features such as vulnerability scanning.
Software Suites
GitHub Packages, GitLab Packages, and Azure DevOps Artifacts each support a subset of artifact types that JFrog Artifactory or Sonatype Nexus does. Still, they allow artifacts to be stored close to or more tightly integrated with the code repositories without needing to manage an external service. Software Suite packages should be considered if you’re already using one of the Source Control Management (SCM) systems and your artifact types are supported.
Specific
Specific artifact repositories host a specific type of artifact, whether Software-as-a-Service (SaaS) or self-hosted. They’re useful if your artifacts are primarily of a single type (e.g., Docker Images). Specific artifact repositories include:
-
NPM for JavaScript packages
-
Docker Hub, AWS Elastic Container Registry (ECR), and Google Container Registry (GCR) for Docker Images
-
Helm Artifact Hub for Helm charts
-
Harbor registry for Kubernetes (Docker images and Helm charts)
Generic
Generic artifact repositories are essentially hosted file systems or blob storage systems such as AWS Simple Storage Service (S3) and can be used for any artifact. Using a generic artifact repository means managing the publication and retrieval logic, though many artifact types provide plugins to help (e.g., Helm S3 Plugin).
Artifact Versioning
Artifact versioning plays a prominent role in the publication process. You and your team must decide on a versioning approach that works well for your use case(s). A typical pattern for versioning is to generate a ‘latest’ deployable artifact for every commit to the base branch of a service repository and generate a versioned artifact using a version naming pattern (such as Semantic Versioning or Calendar Versioning) that corresponds to a release in the repository. The ‘latest’ artifact can easily be automatically deployed to a development environment so that developers always see the latest changes in their application or service in a hosted environment along with other relevant services. When the development environment is behaving as expected, a repository release with a versioned tag is created, generating a corresponding artifact that can be deployed to all other environments.
Using latest artifacts in higher environments, like Production, can be highly risky because code can be changed, published, and deployed to higher environments without passing through lower environment tests like smoke tests in Development or QA environments.
Aside from the ‘latest’ artifact, there are a couple of other artifact versioning approaches which do not follow the “build once, deploy anywhere” pattern: Pull/Merge Request Environments and Hotfix artifacts.
In a Pull/Merge Request Environment, a temporary artifact is generated and deployed to a hosted environment to test changes against other services prior to a merge to the repository’s base branch. Be mindful of how your PR/MR Environments are managed, as they can easily incur a high infrastructure cost.
Hotfix artifacts allow bypassing lower environments to release a bug fix without the need to run through the entire verification process of lower environments. A situation where you might consider hotfix artifacts is if you have a time-based deployment schedule and a need to deploy a critical fix as soon as possible outside of the typical schedule. Hotfix artifacts should generally be discouraged, and their use should be accompanied by rigorous testing in whichever environment they’re deployed into to help ensure compatibility with other hosted services.
Want an in-depth look at Versioning? Check out this post.
How does Continuous Integration Work?
Continuous Integration pipelines are typically defined in Pipeline Runner configuration. Essentially, the steps that you would normally run manually on your local machine to run tests and build artifacts are defined in a pipeline configuration file and checked into a repository along with your code. Part of the pipeline configuration should be to define triggers to run the Continuous Integration automation based on your branch and versioning logic (e.g. run tests on the creation of or commits to a Pull/Merge request). With tests and triggers defined, check in code that meets the trigger conditions, and your Continuous Integration automations will be executed by a Pipeline Runner.
What options are available for Continuous Integration?
Options available for Continuous Integration are very similar to options for Pipeline Runners. If you have a Pipeline Runner, you’ll likely be able to run any pipelines you’ll need for Continuous Integration. If you have uncommon situations like high-CPU/memory tests or required access to privately hosted resources, you’ll want to take that into account when determining which Pipeline Runner will be best for your Continuous Integration pipelines.
For more information on Pipeline Runners, including options, pricing, and getting started, see DevOps Consulting: Pipeline Runners
How much does Continuous Integration cost?
Figuring out how much Continuous Integration will cost can be challenging. Here are some questions you can ask to help narrow in on Continuous Integration costs:
-
What Pipeline Runner are you using?
-
Do you have any special Pipeline Runner conditions like non-Linux Operating Systems or self-hosted runners?
-
How many services need Continuous Integration?
-
How often are you running tests for each service?
-
How long does each test, or set of tests, take for each service?
-
How long does the build process take for each service?
-
How much does it cost for storage of, or access to, artifacts?
-
Do you have team members who know how to build and maintain Continuous Integration pipelines?
How much does Continuous Integration save?
Another valuable question is: How much does Continuous Integration save?
Similarly to Continuous Integration cost, determining how much you will save is not simple, or even quantifiable.
Some quantifiable aspects of Continuous Integration savings are:
-
Shorter developer iteration times
-
Shorter-lived pull/merge requests
-
Reduced errors in deployed services
Some aspects of Continuous Integration savings that is much harder to quantify are:
-
Reduced risk from security vulnerabilities
-
Enhanced maintainability through code cleanliness
Shorter Developer Iteration Times
Most quantitative saving with Continuous Integration comes from shorter developer iteration times because developers will spend less time manually running tests on their local machine; Instead, they can just change their code and check it in. Developer iteration time can be calculated by measuring the frequency of commits or merges into the base branch of a repository.
It should be noted that Pipeline Runners do have an additional startup time which introduces some latency compared to local tests and builds. To mitigate Pipeline Runner startup latency, developers should be encouraged to have multiple work streams so that they can switch contexts to a second task while the Continuous Integration pipelines are running for the first task.
Shorter-lived Pull/Merge Requests
There will also be lowered costs with regard to pull/merge request reviews because many of the tasks necessary in a pull/merge request review can be automated so that other team members can spend less time double-checking test results. You can start to calculate pull/merge request duration reduction by measuring how long pull requests are open as well as gathering feedback from developers on how long they spend reviewing pull/merge requests.
Reduced errors in deployed services
Continuous Integration encourages developers to write tests and keep them up-to-date. When developers maintain tests that are then automated by a pipeline, fewer errors will make it into the base branch where deployable artifacts are created. You can calculate service errors by capturing logs and metrics from services as well as by measuring bug tickets submitted by users or QA teams.
Reduced risk from security vulnerabilities
A much less quantifiable, but arguably much more important, savings from Continuous Integration comes from introducing vulnerability scanners. Vulnerability scanners are tools that scan code and artifacts for known security issues. You can think of vulnerability scanning as an insurance policy for your code and services. It’s possible that there will be no vulnerabilities if you don’t scan. It’s possible that there are vulnerabilities, and your services are never exploited. However, it’s also possible that there is a critical security vulnerability in a library that your code is using, and once it’s deployed, nefarious actions can be taken to gain access to all of your user data, and the cost to resolve a breach can be extremely high (if a resolution is even possible). You should absolutely mitigate that risk whenever possible, and vulnerability scanners can help a lot.
Enhanced maintainability through code cleanliness
Clean, well-written code is easier to read for other developers or even developers revisiting their own code long after it was written. Code smell tools, tools that help developers identify problems in code, and linters, tools that analyze the structure of code to ensure consistency, are a couple of ways to ensure that code is clean and well-written.
How do I get started with Continuous Integration?
The steps performed within your Continuous Integration pipeline will depend on your project’s needs and goals. First, identify the test types you’ll want to perform at Continuous Integration time and write those tests into your project’s codebase. Next, you’ll need to determine what types of artifacts will be generated and deployed. Then, decide on a branching and versioning strategy. Finally, define your Continuous Integration pipelines.
Here’s a quick high-level example of a Continuous Integration pipeline with GitHub Actions which lints the code, tests the code, builds the package and publishes an artifact:
# Name the workflow
name: Test Build Publish
# Define triggers
on:
push:
branches: [main]
# Define the jobs
jobs:
# lint job
lint:
# Define Runner
runs-on: ubuntu-latest
# Define the steps
steps:
# checkout code
- uses: actions/checkout@v2
# lint the code
- name: lint
run: |
npm install
npm run lint
# Test job
test:
# Define Runner
runs-on: ubuntu-latest
# Define the steps
steps:
# checkout code
- uses: actions/checkout@v2
# Run the service tests
- name: Run Tests
run: |
npm install
npm run test
# Build and publish job
publish:
# Define Runner
runs-on: ubuntu-latest
# wait for lint and test jobs to finish
needs: [lint, test]
# Define the steps
steps:
# checkout code
- uses: actions/checkout@v2
# build and publish the artifacts
- name: Build and publish
run: |
npm install
npm publish .Note that the build in this example is wrapped in the npm publish . command, and versioning logic is baked into NPM and its understand of a JavaScript library’s package.json configuration file.
For a hands-on getting started guide, GitHub also provides a skills template for Continuous Integration where you will learn how to create a workflow that runs tests and produces test reports: https://github.com/skills/continuous-integration.
For more information on getting started with Continuous Integration, see DevOps Consulting: Pipeline Runners.
Next Steps
You should now have a decent idea about the role Continuous Integration plays in automated software delivery.
Having a high-level understanding is only the tip of the iceberg for Continuous Integration, however, and there are many features, strategies, and patterns that you and your teams can leverage to take full advantage of Continuous Integration and enhance your Software Delivery Automation.
DevOps Consulting Services
Regardless of where you are on your DevOps maturity journey, you should consider leveraging the expertise of 3rd parties or vendors, like Bitovi DevOps Consulting. You can easily bring in DevOps and operations expertise to your projects to bootstrap your infrastructure, automations, DevOps culture, and maturity plan.

Previous Post

