









.svg)





.png)
Back of Napkin - Fast Map/List Projections
WARNING! "Back of the napkin" posts are rushed articles that we publish to get out an thought or idea. You probably should not be reading this.
This "back of napkin" post introduces a difficult problem we are trying to solve for CanJS, our efforts to solve it, and what we think the solution will look like. If you have any thoughts or advice, please let us know!
The problem
If you've used CanJS, or I suspect any popular JavaScript framework, you are constantly projecting one form of list data into another. For example, in TodoMVC, you might get all of the todos from the server, and then filter them to show only the completed ones for a particular view. This code often looks like:
var completed = todos.filter(function(todo){
return todo.complete
});
In the CanJS example, the todos to be displayed is defined here. It looks like:
displayList: function () {
var filter = route.attr('filter');
return this.todos.filter(function (todo) {
if (filter === 'completed') {
return todo.attr('complete');
}if (filter === 'active') {
return !todo.attr('complete');
}
return true;
});
}
One of the great things about CanJS, is that if the route's filter property changes, any of the todos's completed property changes, or todo's are added/removed from the todos list, the displayList property will be updated and the necessary DOM manipulations will be made accordingly by the template engine.
While this API is incredibly convenient and intuitive for application developers, at its core a "new" list is being created by inefficiently iterating over the todos list for every relevant change.
Ideally for every individual "change" (add/remove/update) to the todos list, CanJS would evaluate the change and when necessary make a single appropriate change to the displayList. Similar to the way CanJS only makes the relevant changes to the DOM that are necessary based on the dependant properties that have changed. Obviously, much more efficient than re-rendering the entire page.
The goal
Myself and Justin Meyer have been exploring potential solutions to this problem in the can-derive project. Here's an example of what we hope to accomplish:
var numbers = new can.List([1, 4, 9]);
var powers = numbers.map(function (num) {
return Math.pow(num, 2);
});numbers.attr(); //-> [1, 2, 3]
powers.attr(); //-> [1, 4, 9]// Add
numbers.push(4);numbers.attr(); //-> [1, 2, 3, 4]
powers.attr(); //-> [1, 4, 9, 16]// Remove
numbers.shift();numbers.attr(); //-> [2, 3, 4]
powers.attr(); //-> [4, 9, 16]// Change
numbers.attr(0, 4);
numbers.attr(); //-> [4, 3, 4]
powers.attr(); //-> [16, 9, 16]
For the most part, CanJS's internals provide a lot of the necessary infrastructure that would be needed to wire something like this up. CanJS emits the necessary events to know when values have been added to or removed from a map or list. We also know when properties have changed on the items inside of those maps/lists, and can easily make properties dependent on one or more others.
The tricky bit becomes correctly and efficiently manipulating the derived/projected map/list as a result of these emmitted events. Especially in the case of filtered lists.
Filtered lists
Filtered lists pose a unique challenge to the goals of the can-derive project. The reason being that changes to the items in the source list may result in that item being added to or removed from the derived filtered list. But at what index? Let's simulate this with the todos example referenced above:
var todos = new can.List([
{ title: 'Hop', completed: false },
{ title: 'Skip', completed: true },
{ title: 'Jump', completed: false },
{ title: 'Leap', completed: false }
]);
var completedTodos = todos.filter(function (todo) {
return todo.attr('completed');
}).map(function (todo) {
return todo.attr('title');
});
completedTodos.attr() //-> ['Skip']
Simple enough, so far. When an item that met the requirements of the filter was encountered, it was placed into the completedTodos at the only possible index: 0. But let's see what happens when the next item is added to completedTodos list:
todos.attr('3.completed', true); // Set "Leap" to completed
completedTodos.attr() //-> ['Skip', 'Leap']
Naturally, we'd expect that "Leap" would be inserted after "Skip" because "Leap" came after "Skip" in the original list. Unfortunately, in order to determine that "Leap" should be inserted at index 1, we needed to compare the "Skip" item's source index (1) to the source index of the "Leap" item (3).
In essense, this solution involves a sorting algorithm being applied to some private "source index" property. Or in other words, this solution requires O(n) time to determine the correct index - which is slow, so we started looking into other options.
Research
First, we brainstormed amongst a few of the other Bitovi developers. Then we asked for help on stack exchange. Here's how Justin phrased the question:
Say I have a source list like: ["a","b","c","d"] and want to run a capitalization filter so if I change, "b" to "B", my derived list looks like ["B"]. Next, if I change my source list's "d" to "D", the derived list should look like ["B","D"].
Is it possible to make the insertions and removals in the derived list, while maintaining order, in faster than O(n) time?
Finally, I'd like to be able to know the index of where the insertion or removal takes place in the derived list in faster than O(n) time.
Lastly we stewed on the idea for a day or two and then regrouped to sketch out and refine our plan a bit more.
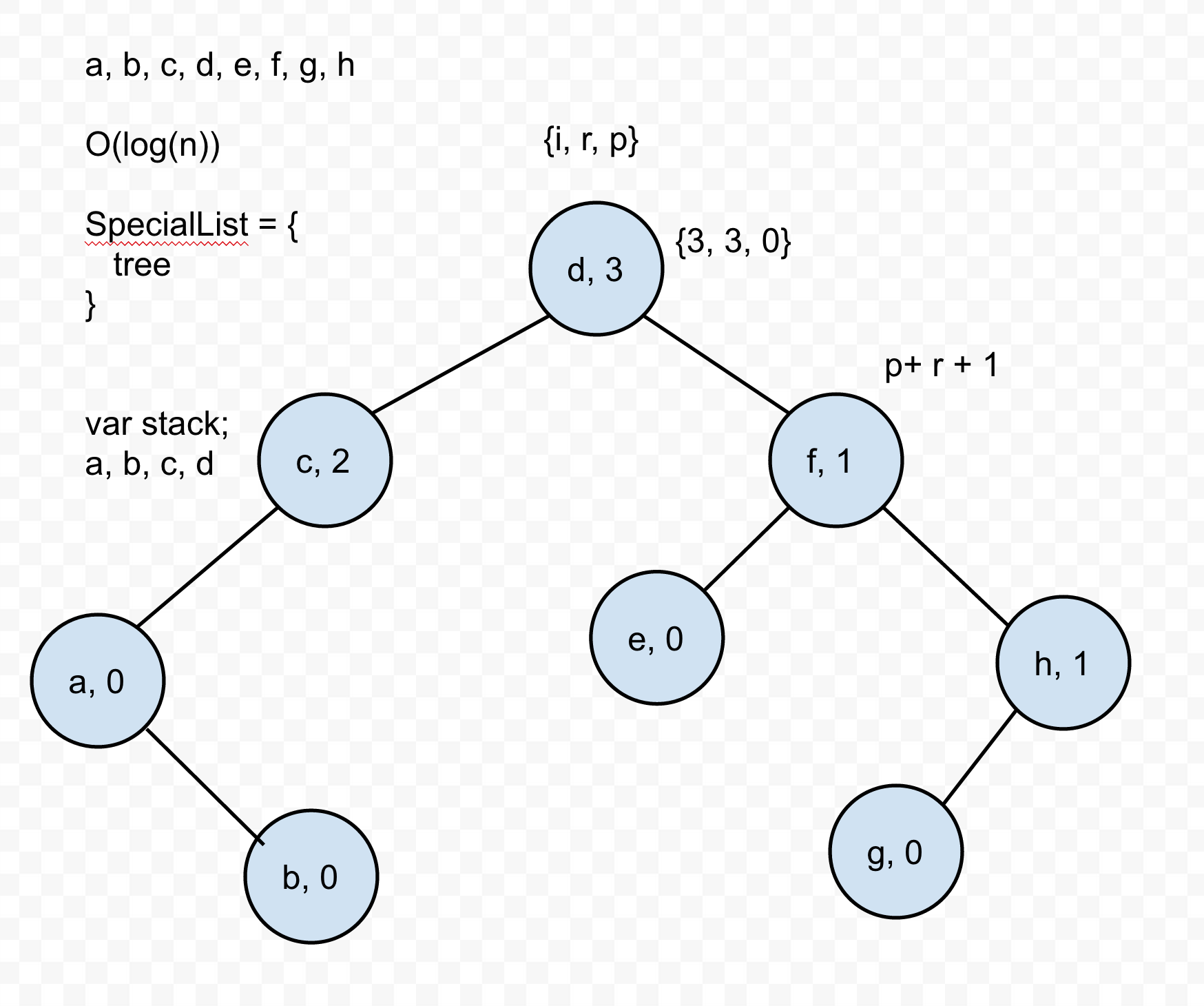
The plan
The rough idea is to back our derived list with a balancing binary search tree. We'll use the "source index" as the key so that the binary search tree will position the inserted items at the correct index relative to the existing items in O(log(n)) time. As we're traversing the tree to make the insert, any time we choose "left" or "less than", we'll increment a counter at that node.
At this point the items in the derived list will be sorted correctly, but they're indexed by a key that makes them more like a can.Map than a can.List. To get around this we'll use the incremented "left counter" to calculate each item's "derived index" whenever the list is accessed by .attr() or .indexOf(), etc.
This approach seem promising, so keep an eye out for our next update regarding the can-derive project.
Other thoughts
It would be nice if JavaScript provided a richer collection of data structures and algorithms. We are thankfully finally getting hash maps. And Lodash's indexOf provides binary search.
Previous Post

Next Post
